近期,我院服装设计智能化重点实验室鲁棒视觉智能感知技术团队2022级硕士研究生成澳彬同学撰写的题为《TextSRFormer: Multi-head axial self-attention transformer for scene text image super-resolution》的学术论文在国际期刊《Signal Processing》(DOI: 10.1016/j.sigpro.2025.110362),中科院工程技术领域SCI二区期刊)上发表。
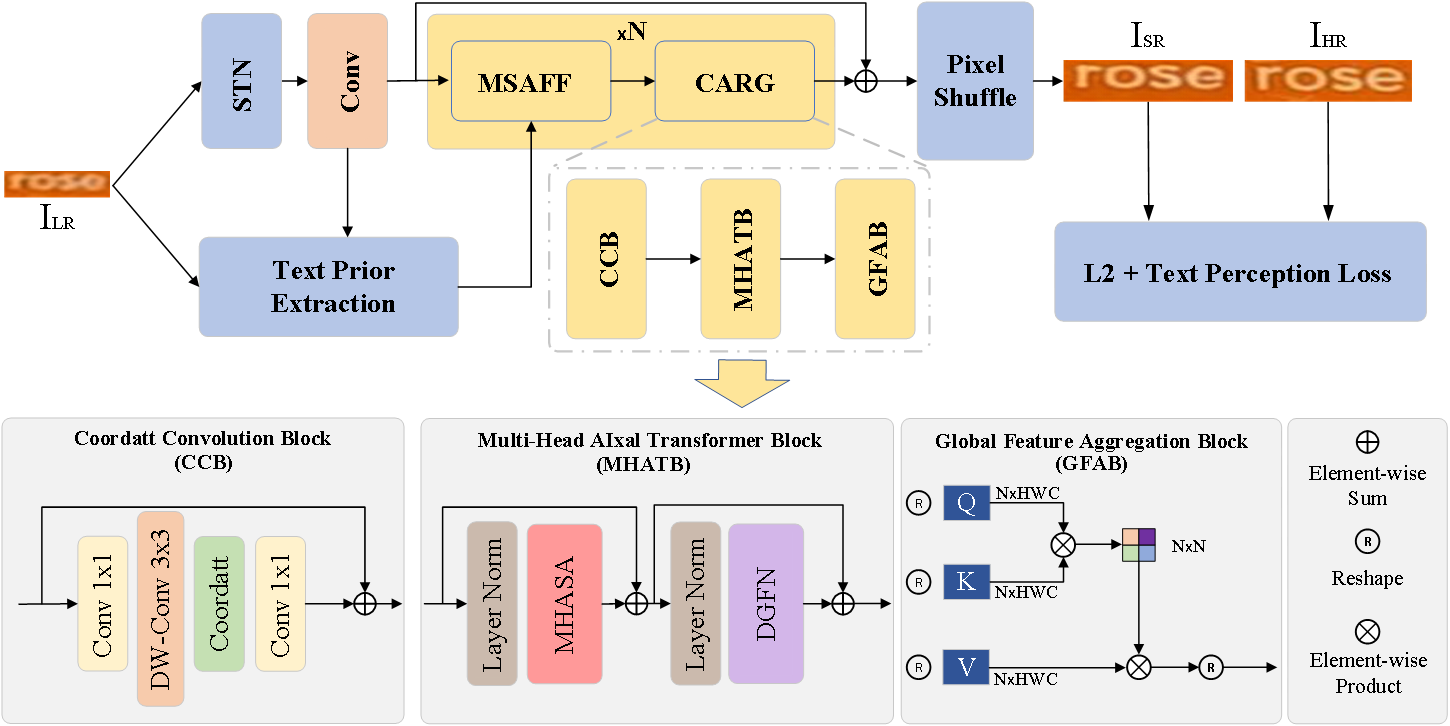
该论文针对传统卷积神经网络全局感受野受限及文本图像语义信息利用不足的问题,提出了一种融合语义先验与多头轴向自注意力的自然场景文本图像超分辨方法。该方法采用多头轴向注意力Transformer块与全局特征聚合模块的残差组替代传统顺序残差块,分别从高度、宽度和通道三个维度提取文本图像的局部结构细节,并实现多层级特征的高效融合,显著拓展了深度网络的横、纵向感受野,从而提升复杂退化条件下文本图像的特征表达能力。同时,为进一步增强模型的语义理解与重建性能,论文构建了一种新的多尺度注意力融合机制,实现文本语义先验特征与图像深度特征的高效交互融合。实验结果表明,该方法在自然场景文本图像超分辨任务中表现优异,在识别精度和视觉清晰度两方面的定性和定量性能指标上均取得了显著提升,为多模态服装图像识别、文本OCR、智能驾驶等相关视觉下游任务提供了有力技术支撑。
人物链接:

成澳彬,男,2025年6月毕业于西安工程大学计算机科学学院,获计算机科学与技术学术型硕士学位。主要研究方向为模式识别与人工智能、深度学习、计算机视觉和场景文本图像超分辨。目前就职于众芯汉创(江苏)科技有限公司,担任人工智能算法工程师。(撰稿:成澳彬 审核:张凯兵)



